Tracking Dark-Web Infrastructure

Disclaimer – I am not endorsing you do this or am in anyway liable for how you use this information or script. Check your laws and practice good OPSEC. You are responsible for your actions.
Looking for weaknesses over TOR is very much different than over the Clearnet. The way in which TOR works allows for a high level of anonymity. So, let’s just quickly discuss what TOR is.
TOR, or as it’s known – The Onion Router, is a network specifically built for privacy. The network traffic bounces your traffic through volunteer-run relays. Each hop peels a layer of encryption (like an onion) so in essence no single relay knows both who you are and where you are going.
More importantly for this article and endeavour, Tor hosts .onion services, which are also known as ‘hidden services’ , these are websites that run inside the TOR network and are reached through a Tor browser or a Tor client. A typical example is that we all know an IP address in the internet resolves to a domain name ) 142.251.30.113 resolves to google.com (At the time of writing anyway)
.onion addresses are – OnionAddress = base32(PublicKey + Checksum + Version) + “.onion” which then would give you something like this (expyuzz4wqqyqhjn.onion), an example only.
It is important to note at this point that not all Tor hidden services are illegal!
So just to quickly recap why TOR differs from the Clearnet
Clearnet sites rely on DNS. Tor sites use self-authenticating onion addresses derived from cryptographic keys.
Clearnet routes directly over the public internet. Tor builds ephemeral circuits through multiple relays.
Clearnet discovery is dominated by search engines. Tor discovery is fragmented directories come and go, and many sites block indexing.
Clearnet attribution often leverages hosting clues, registrar data, trackers, and IP history, Tor deliberately strips these out or obscures them.
There are numerous scripts that probably do the same, but I wanted something that was able to capture evidence reproducibly, build a case of file of sorts, which I think I managed, but still a lot more improvements can be made.
I wanted to be able to discover and index onion sites for threat intel, extract useful non intrusive signals, metadata, open ports, crypto addresses etc and any external pivot points, such as Clearnet leaks or of that nature. It has to be passive by default but also have some active portions for those systems I have permission to test. The active part should just test ssrf/lfi. – directories at a later date perhaps.
You can find the script here at ThreatInsightsdev/TorIntelScan: TorIntel Scan – a research-oriented TOR reconnaissance and evidence-capture tool.
All options are below to enable the script to run.
python3 torscanner1.py –url threeamkelxicjsaf2czjyz2lc4q3ngqkxhhlexyfcp2o6raw4rphyad.onion –enrich-clearnet –mirror-detect –index-file corpus_index.json –output torintel_output.jsonl –evidence –case-dir case_example –warc –queue-wait 300 –queue-log queue_log.jsonl –wait-selector “main,#content” –max-wait 300 –timeline –snapshot-every 10
Once this is executed you can see the files it produces below;
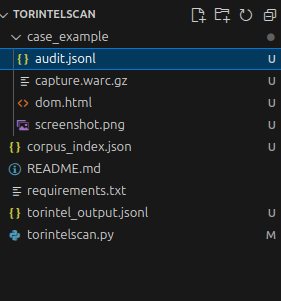
The key here for me was the audit.jsonl, which keeps track everytime I run the script.
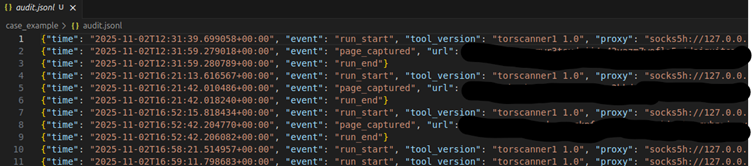
Then the full output is dumped into the output.jsonl and looks something like the below; you can see it extracts interesting artefacts
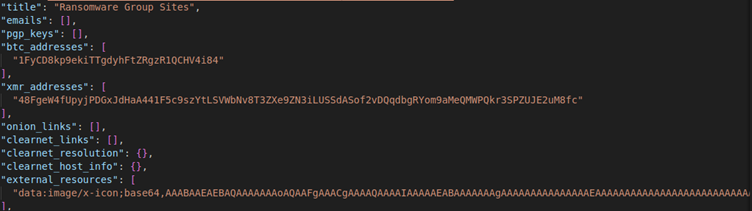
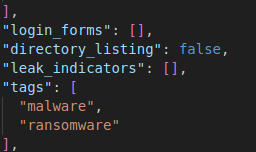
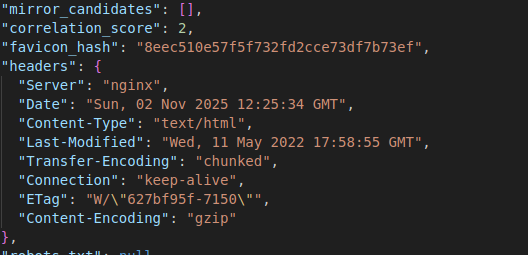
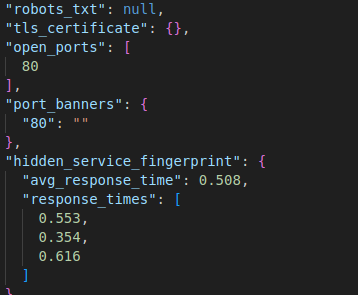
I think there is enough detail here to start building up a picture, or certainly enough to start and investigation and then you can pivot over to Maltego and start building up a bigger picture of things.
NOTE: Exercise caution with the screen shot evidence, personally I wouldn’t run this option initially until you understand what you’re working with.
How the Script Works
- Fetch the target .onion page over Tor.
- Parse with BeautifulSoup → text, links, forms, headers, resources.
- Tag & extract: emails, PGP blocks, BTC/XMR, Telegram handles, JS endpoints, leak indicators.
- Clearnet enrichment (if present): resolve domains; optional ASN/PDNS lookup.
- Correlate: compute favicon MD5, SimHash for text, mirror candidates against a local index.
- Evidence (if enabled): headless screenshot, DOM, hashes, optional WARC; queue-aware waits.
- Optional crawl: follow discovered onion links to expand coverage—rate-limited and logged.
- Output: JSONL per page (machine-readable), plus an evidence folder for auditors.
Practical CTI Uses which is its intended use case
- Brand/infrastructure tracking, Is a “new” market actually a clone of a taken-down site?
- Ransomware monitoring in some sense as you can Extract crypto addresses, cross-reference notes and contact channels, flag potential victims for outreach.
- Identify clearnet pivots or reused comms handles that enable lawful notices.
- Possible takedown preparation because you can package evidence with hashes and WARCs to meet partner or legal evidentiary standards (in some countries jurisdiction)
- Horizon scanning in general, allows you to crawl with conservative depth to map emergent ecosystems (forums, brokers, data-leak blogs).

